Today you will learn how to find the right embedding model for your RAG application. Let’s get started!
Problem❗
Text embeddings are vector representations of raw text that you compute using an embedding model
An embedding model maps your raw text into a vector
These vectors representations are then used for downstream tasks, like
Classification → for example, to classify tweet sentiment as either positive or negative.
Clustering → for example, to automatically group news into topics.
Retrieval → for example, to find similar documents to a given query.
Retrieval (the “R” in RAG) is the task of finding the most relevant documents given an input query. This is one of the most popular use cases for embeddings these days, and the one we will focus on today.
There are many embedding models, both open and proprietary, so the question is:
What embedding model is best for your problem? 🤔
Let me show you how to find the right model for your RAG application ↓
Solution 🧠
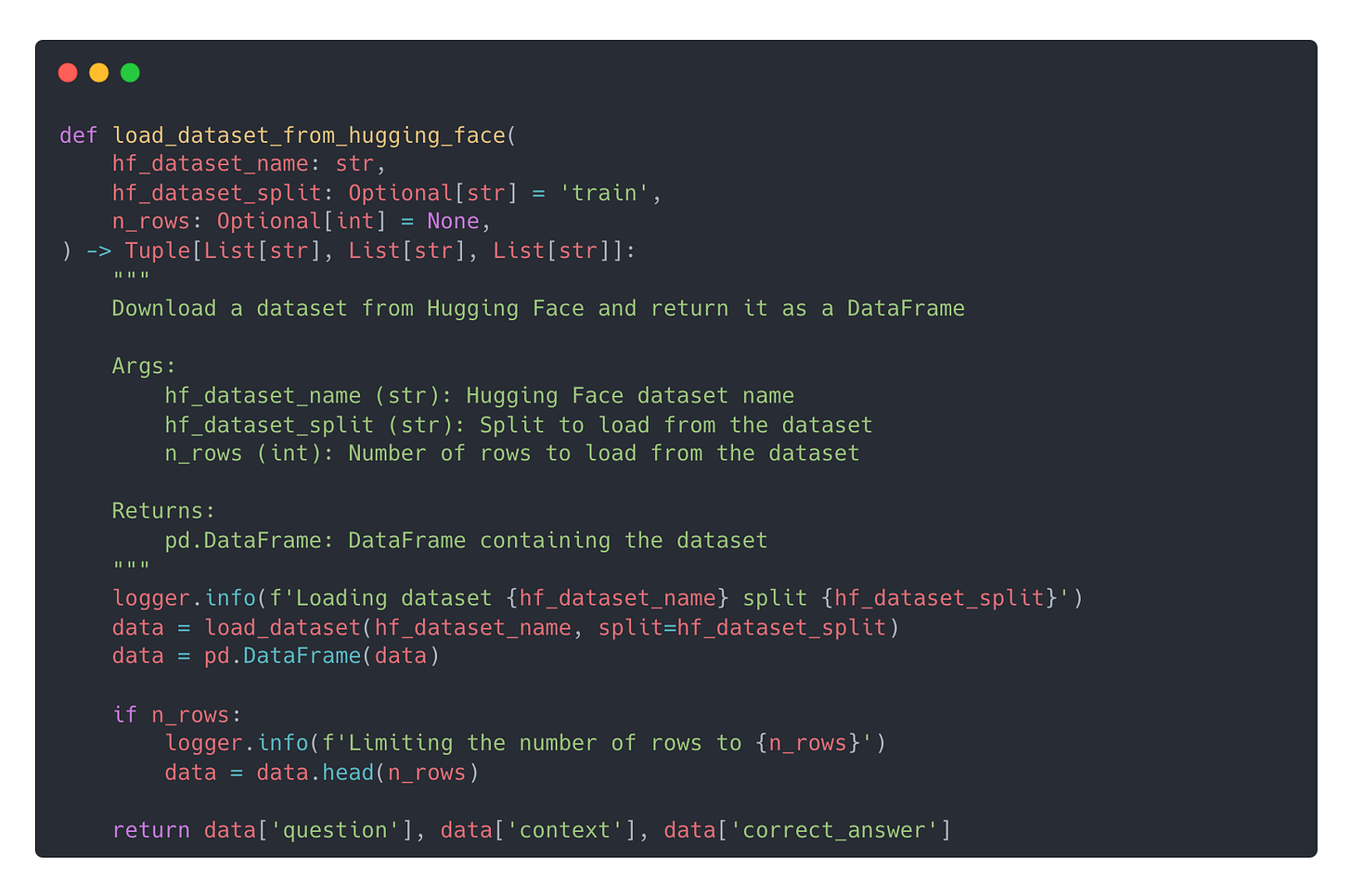
First, go to the Massive Text Embedding Benchmark (MTEB) Leaderboard, to find the list of best embeddings models for the retrieval task in your language, for example English.
As per today (April 18th 2024) the number 1 model in the leaderboard is Salesforce/SFR-Embedding-Mistral with
Embedding quality: 59%, measured with the average Normalized Discounted Cumulative Gain (NDCG) over 15 different datasets.
Model size: 7.1 billion parameters
Top 10 embedding models as per April 18th 2024
At this point you might think that Salesforce/SFR-Embedding-Mistral is the model you need… and you are probably wrong 😵💫
Why ❓ Because embedding quality is not the only measure you should look at when you build a real-world RAG app. Model size matters, because larger models are slower and more expensive to run.
For example 💁 The 7th model in the leaderboard is snowflake-arctic-embed-l with
Embedding quality of 55.98% → 5% worse than the leader.
Model size: 331 million parameters → 95% smaller than the leader
So, if you are you willing to trade 5% of quality, for 95% cost reduction, you would pick snowflake-arctic-embed-l.
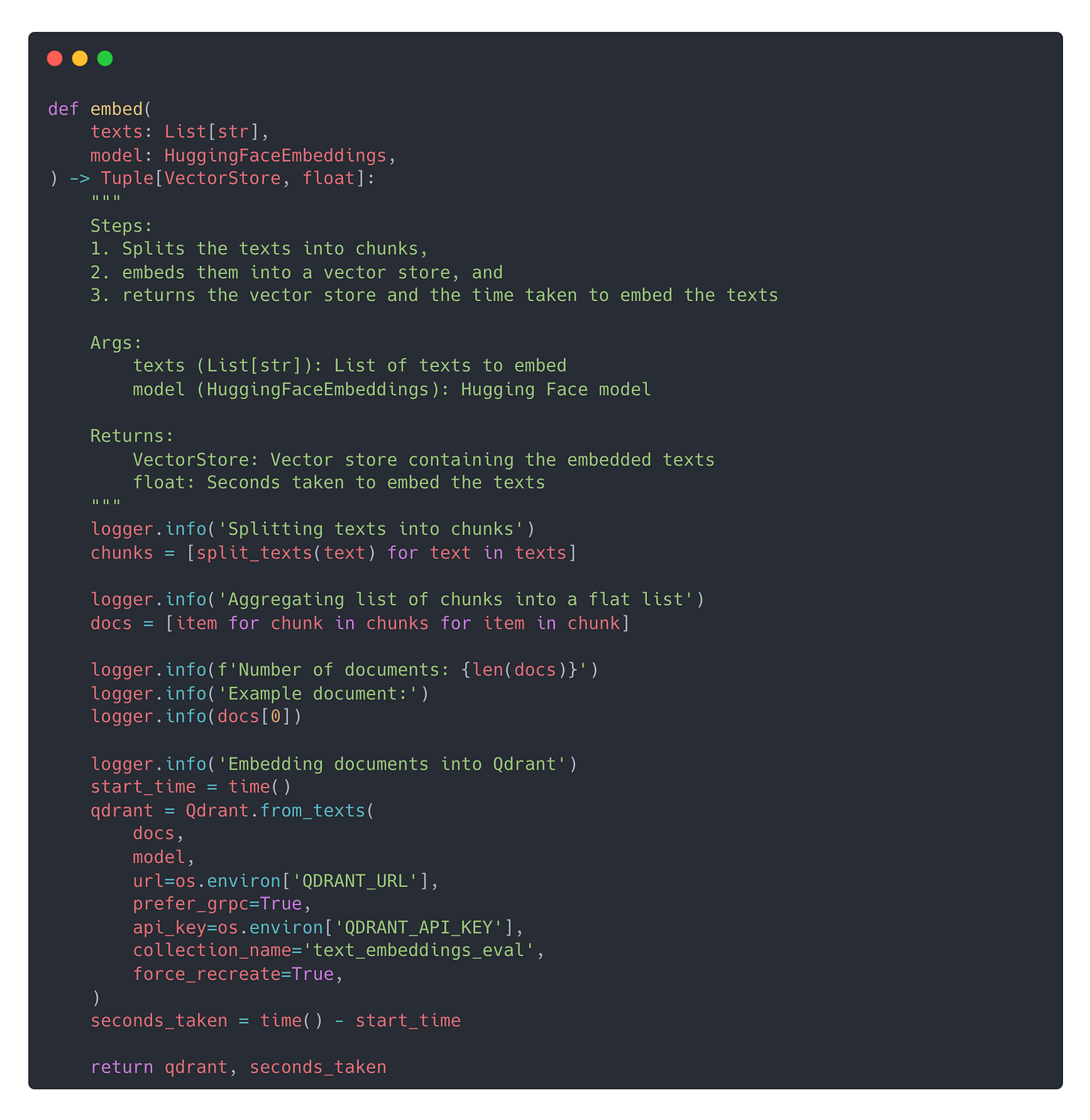
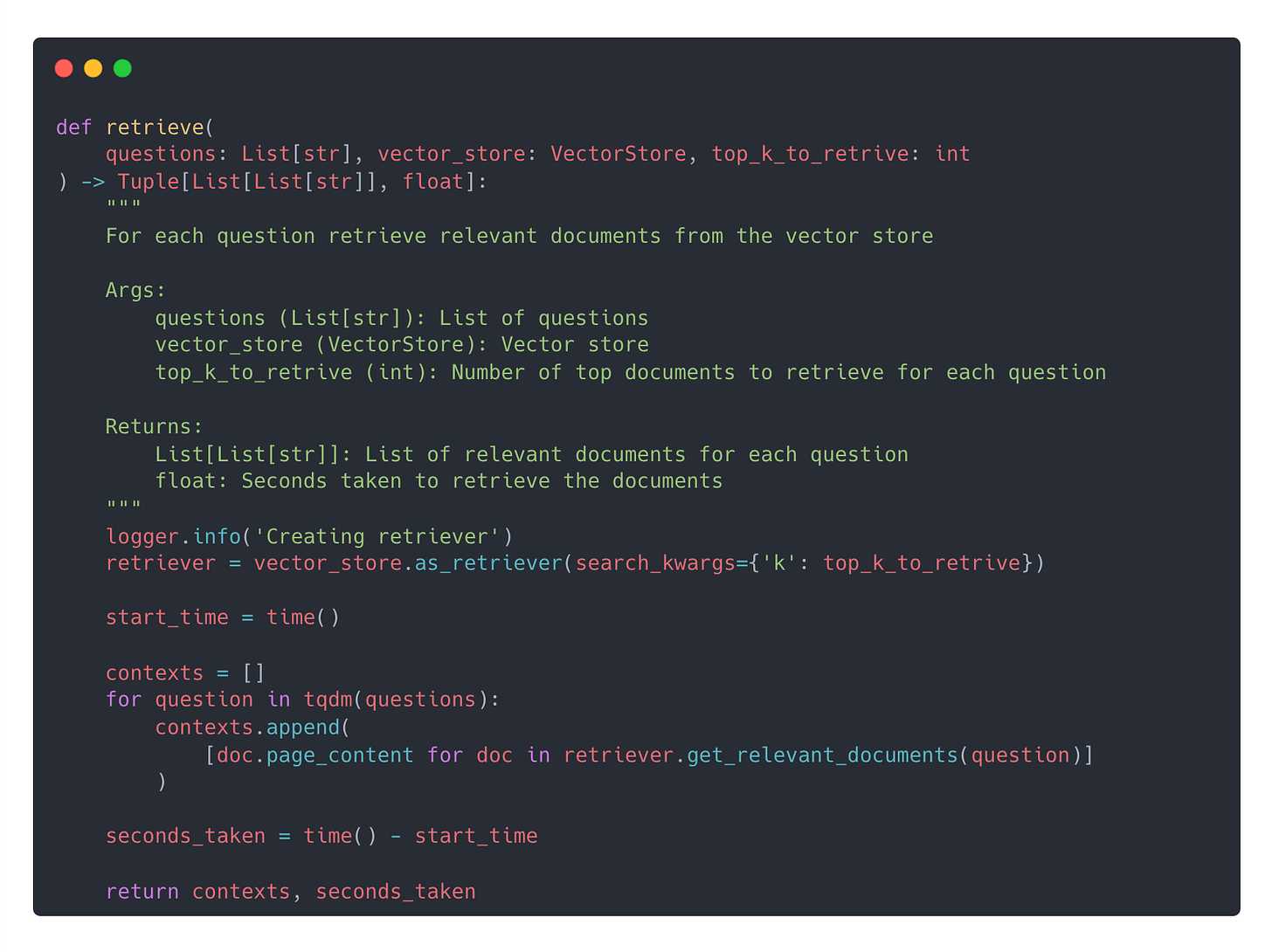
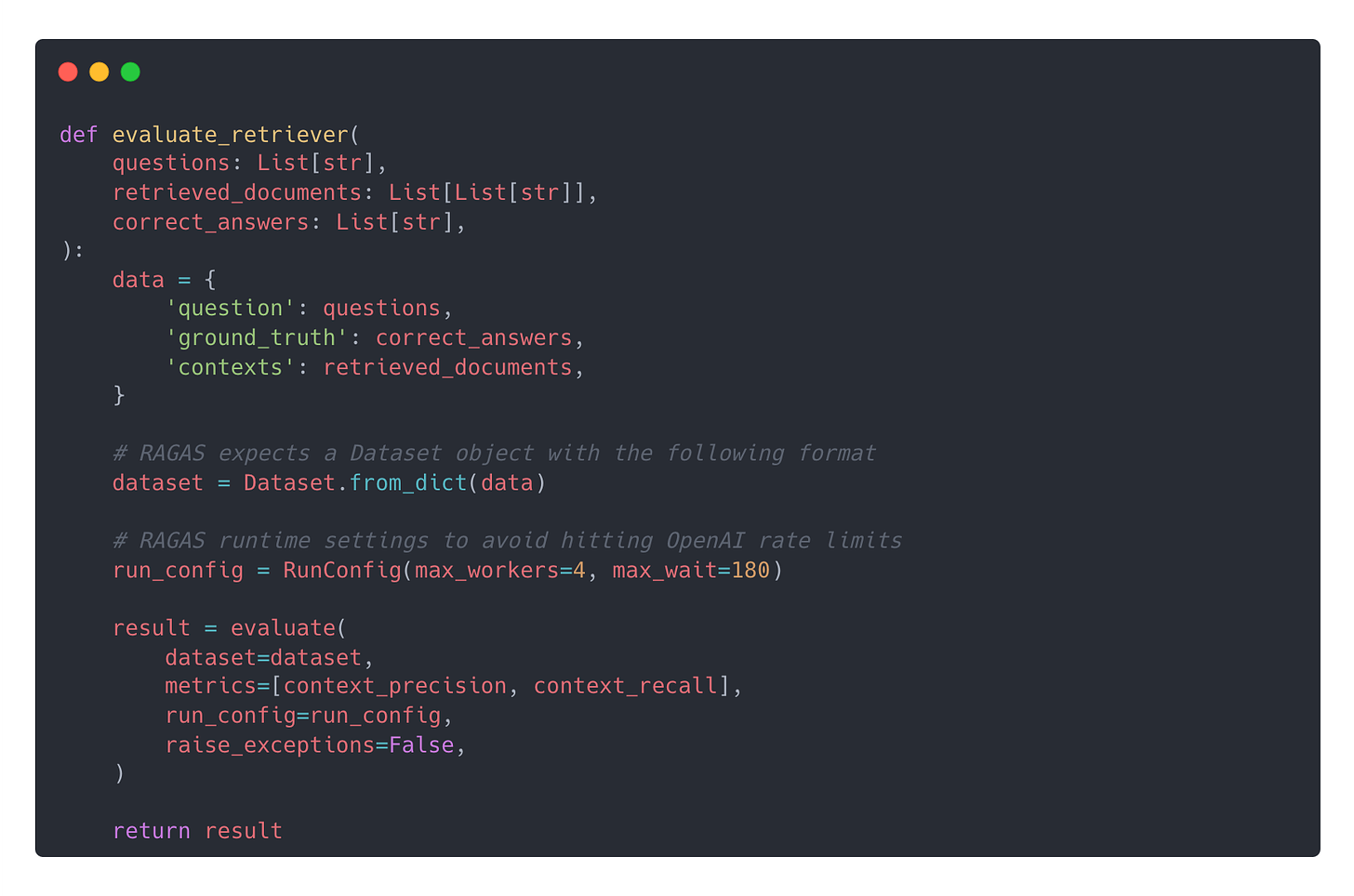
In general, to find the sweet spot ⚖️ between embedding quality and cost, you need to run a proper evaluation of your retrieval step, using your
Dataset → e.g. explodinggradients/ragas-wikiqa
Vector Db → e.g. Qdrant
Other important RAG hyper-parameters, like your chunk size and chunk overlap.
Let’s go through an example with full source code.
You will need an OpenAI API key, because ragas, the framework for RAG evaluation we use, will be making calls to `GPT-3.5 Turbo` to evaluate the context information quality.
Qdrant
We will use Qdrant as the VectorDB, so you also need to create a FREE account on Qdrant.cloud to get your QDRANT_URL and QDRANT_API_KEY
Step 4. Select the models and dataset you want to evaluate
Update the list of models you want to evaluate and the dataset in the config.yml
Generative AI is very cool, but the reality is that most real world business problems are solved using tabular data and predictive ML models.
If you are interested in learning how to build end-2-end ML systems using tabular data and MLOps best practices, join the Real-World ML Tutorial + Community and get lifetime access to
→ 3 hours of video lectures 🎬 → Full source code implementation 👨💻 → Discord private community, to connect with me and 350+ students 👨👩👦